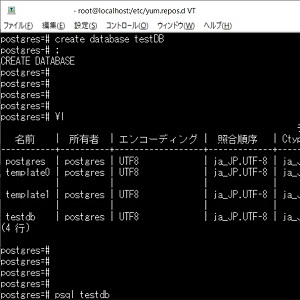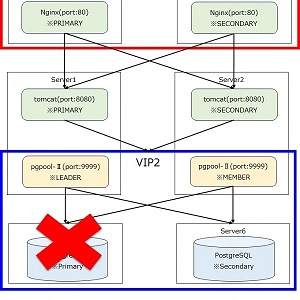
こちらの記事はnoteに移動しました
Excelおすすめ記事
ミドルウェアおすすめ記事
この記事を書いた人
個人事業のシステムエンジニアです
前職はゴリゴリの営業マン(保険売りまくってた)
大抵のプログラミングはこなせます
環境構築もそれなりに出来るかと思います
趣味はゲーム、競馬、食べ歩き、旅行など
備忘と記録を残すためにブログを執筆しております
お仕事のお話は問い合わせフォームからお気軽にお声掛けください♪
前職はゴリゴリの営業マン(保険売りまくってた)
大抵のプログラミングはこなせます
環境構築もそれなりに出来るかと思います
趣味はゲーム、競馬、食べ歩き、旅行など
備忘と記録を残すためにブログを執筆しております
お仕事のお話は問い合わせフォームからお気軽にお声掛けください♪
最近書いた記事