記事をnoteに移動しました!
お手数ですが、上記リンクからご覧くださいませ。
- VMware × CentOS関連索引
- VMWare Workstation Player×CentOSで自PCに仮想環境を構築する
- VMWare × CentOSの環境にSSH通信する
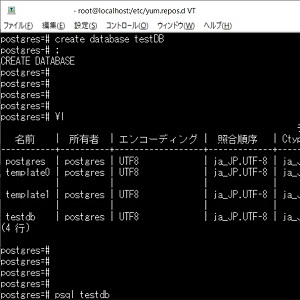
- CentOSにPostgreSQL(15)をインストールする
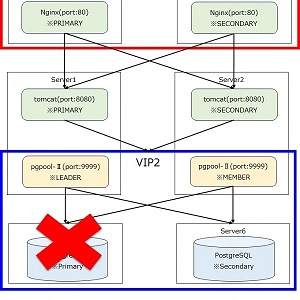
- pgpoolでPostgreSQLをレプリケーション&フェイルオーバー
- VMWareを立ち上げたら別のプロセス使用中エラーが出た
- NginxにDigest認証を組み込む方法
- NginxをKeepAliveで冗長化&Tomcatへロードバランス
- 構築後、主系をダウンさせての動作確認
- PostgreSQLバックアップ&リストア
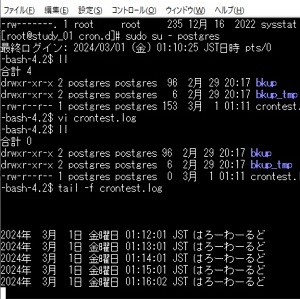
- 時間が来たら実行する「cron」の使い方を解説
- PostgreSQL同士でレプリケーションセット
- ZABBIX構築してローカルからリモートアクセス
Excelおすすめ記事
ミドルウェアおすすめ記事
この記事を書いた人
個人事業のシステムエンジニアです
前職はゴリゴリの営業マン(保険売りまくってた)
大抵のプログラミングはこなせます
環境構築もそれなりに出来るかと思います
趣味はゲーム、競馬、食べ歩き、旅行など
備忘と記録を残すためにブログを執筆しております
お仕事のお話は問い合わせフォームからお気軽にお声掛けください♪
前職はゴリゴリの営業マン(保険売りまくってた)
大抵のプログラミングはこなせます
環境構築もそれなりに出来るかと思います
趣味はゲーム、競馬、食べ歩き、旅行など
備忘と記録を残すためにブログを執筆しております
お仕事のお話は問い合わせフォームからお気軽にお声掛けください♪
最近書いた記事